
 微信号:
微信号: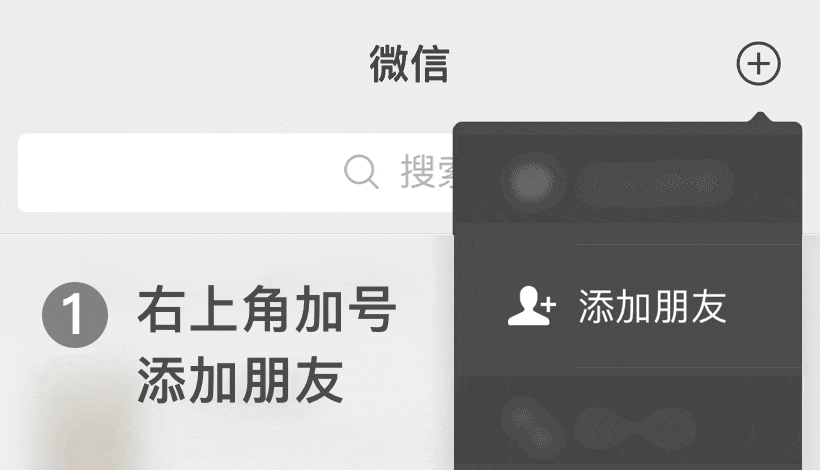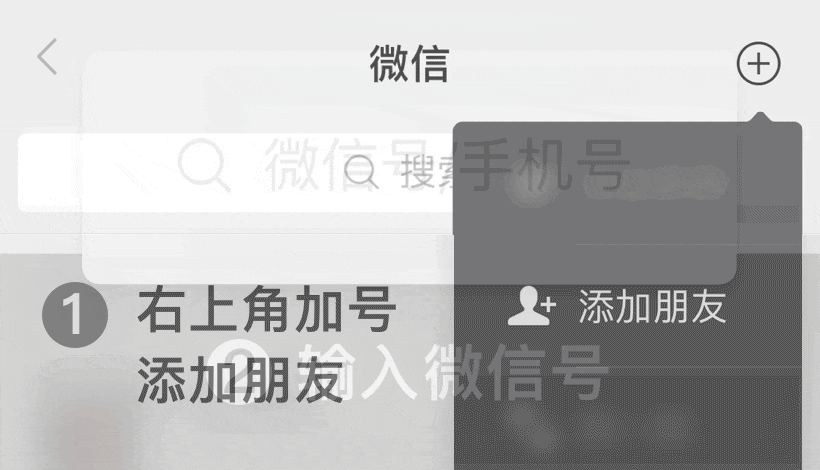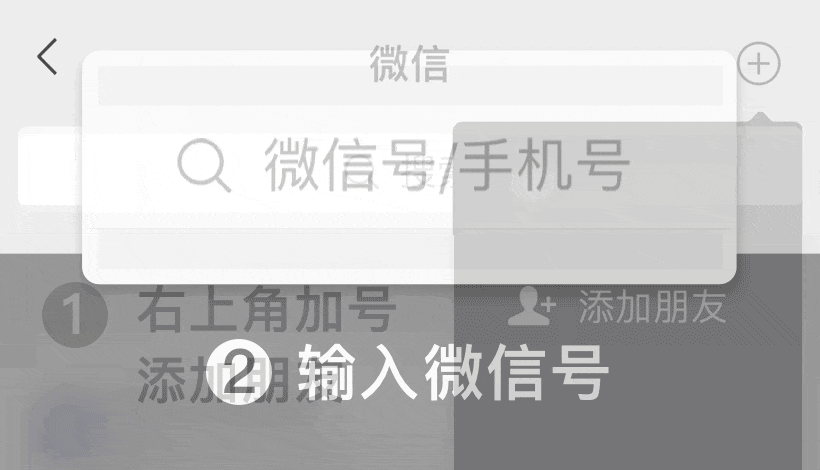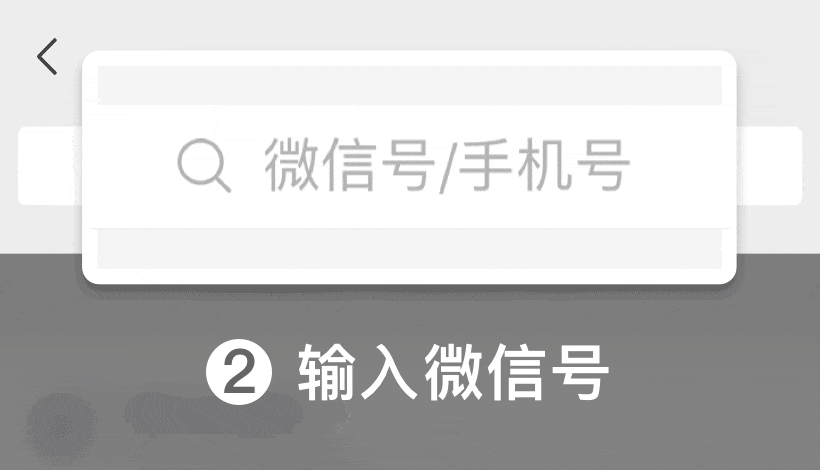


-
 全国服务热线
全国服务热线
- 131-9330-7412
浪潮元脑NF5698A7服务器能够同时部署、运行DeepSeek R1与DeepSeek V3模型
来源:www.3qrc.cn | 发布时间:2025年04月08日“快思考”与“深度思考”并行,赋能企业效率提升
DeepSeek V3 与 DeepSeek R1 模型均基于混合专家架构(MoE)与多头潜在注意力(MLA)技术底座,但在技术路径与应用定位上展现出差异化发展方向。
■ DeepSeek V3 (671B/685B):以低成本和高通用性见长,适合广泛的应用场景,如智能客服、多语言翻译、内容生成等,能够高 效处理各种文本生成、摘要和对话任务。新的DeepSeek V3-0324模型在长文本理解、多轮对话与通用问答等方面表现提升明显;
■ DeepSeek R1 (671B):通过强化学习实现了专业领域的推理突破,专注于复杂逻辑推理任务,如数学证明、代码生成和决策分析,支持“思维链”输出,展示推理过程,提升透明度和可信度。
DeepSeek一体机作为一种高 效、经济、安全的私有化交付方式,已逐渐成为企业用户快速实现本地化部署DeepSeek R1 671B或DeepSeek V3 671B/685B模型的重要途径。企业在实际业务运行中,简单和实时任务要求快速推理,复杂逻辑、跨领域、创造性任务则需要深度思考。如何通过一台DeepSeek一体机同时实现“快思考”和“深度思考”,企业根据任务特性合理分配两种推理模式,提升问题解决的效率与质量,充分发挥DeepSeek在实际业务场景中的价值,这也成为了业界更为关注的研究方向。
元脑企智DeepSeek一体机,支持671B R1和V3同机运行
浪潮信息团队针对用户的这一迫切需求,从AI 服务器、推理框架、大模型应用软件等多个方面开展适配与优化工作,推出元脑企智DeepSeek一体机,已适配支持DeepSeek R1 671B、DeepSeek V3 671B/685B模型,实现了“快思考”与“深度思考”能力的全面融合,助力企业用户在全场景下充分释放DeepSeek大模型能力。
元脑企智DeepSeek一体机NF5698A7原生支持FP8计算引擎,以1536GB HBM3显存、5.3 TB/s 内存带宽实现了显存容量与通信效率的黄金组合,适配 DeepSeek R1模型“短输入长输出、显存带宽敏感”的技术特性,单机支持全量DeepSeek R1与V3模型推理情况下,仍保留充足的KV缓存空间,配合896 GB/s P2P带宽的高速通信架构,在保障单机部署张量并行效率的同时,实现大模型推理解码阶段的加速,为DeepSeek R1与V3模型提供强劲算力支撑与稳定运行保障。
此外,得益于大显存,NF5698A7服务器能够同时部署、运行DeepSeek R1与DeepSeek V3模型,为用户带来了“开箱即用”的解决方案,降低了DeepSeek模型部署的技术门槛,快速实现大模型在业务中的应用。
【相关文章】






陕西益东网络信息科技有限公司
 微信咨询
微信咨询
 手机访问
手机访问
 添加微信
添加微信
 联系我们
联系我们
 电话咨询
电话咨询